
Kvrocks is an open-source key-value database that is based on rocksdb and compatible with Redis protocol. Intention to decrease the cost of memory and increase the capability while compared to Redis. We would focus on how we use RocksDB features to improve the performance of the Redis on disk. Hopes this helps people who want to improve performance on RocksDB.
Background
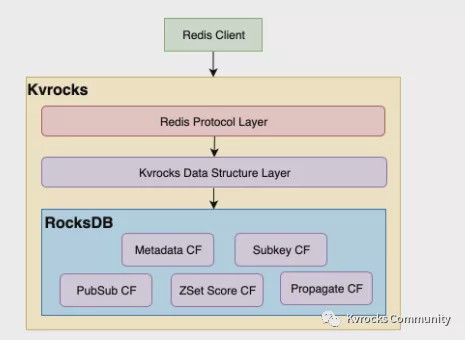
Let's have a look at how Kvrocks uses the RocksDB before introducing performance optimization. From the implementation side, Kvrocks would encode the Redis data structure into the key-values and write them into the different RocksDB's column families. There's five column family type in Kvrocks:
- Metadata Column Family: used to store the metadata(expired, size..) for complex data structures like Hash/Set/ZSet/List, also string key-value was stored in this column family
- Subkey Column Family: used to store key-values for complex data structures were mentioned before
- ZSetScore Column Family: only store the score of the sorted set
- PubSub Column Family: used to store and propagate pubsub messages between the master and replicas
- Propagated Column Family: used to propagate commands between the master and replicas
Also, Kvrocks uses the RocksDB WAL to implement the replication, for more detail can see:
- Kvrocks: An Open-Source Distributed Disk Key-Value Storage With Redis Protocol
- How to implement the Redis data structures on RocksDB
We can have a glance at the Kvrocks architecture from 10,000 feet view:
How to profile RocksDB
Memtable Optimization
Currently, Kvrocks was using the SkipList Memtable. Compared with the HashSkipList Memtable, it has better performance when searching across multiple prefixes and uses less memory. Kvrocks also enabled the whole_key_filtering the option which would create a bloom filter for the key in the memtable, it can reduce the number of comparisons, thereby reducing the CPU usage during point query. Related configuration:
metadata_opts.memtable_whole_key_filtering = true
metadata_opts.memtable_prefix_bloom_size_ratio = 0.1
Data Block Optimization
Previously, Kvrocks used binary search when searching the data block, which may cause CPU cache miss and increase the CPU usage. As the point query was the most used scenario in the key-value service, so Kvrocks switched to the hash index to reduce the binary search comparisons. Official test data shows that this feature can reduce CPU utilization by 21.8% and increase throughput by 10%, but it will increase space usage by 4.6%. Compared with disk resources, CPU resources are more expensive. Under the trade-off, Kvrocks chose to enable the Hash index to improve the efficiency of point queries.
Related configuration:
BlockBasedTableOptions::data_block_index_type = DataBlockIndexType::kDataBlockBinaryAndHash
BlockBasedTableOptions::data_block_hash_table_util_ratio = 0.75
Filter/Index Block
The old version of RocksDB used Bloom Filter of BlockBasedFilter type by default. The basic mechanism is to generate a Filter for every 2KB of Key-Value data, and finally form a Filter array. When searching, first check the Index Block, and for the Data Block that may have the Key, then use the corresponding Filter Block to determine whether the key exists or not.
The new version of RocksDB optimizes the original Filter mechanism by introducing Full Filter. Each SST has a Filter, which can check whether the Key exists or not in the SST and avoid reading the Index Block. However, in the scenario with a large key number in the SST, the Filter Block and Index Block will still be larger. For 256MB SST, the size of Index and Filter Block is about 0.5MB and 5MB, which is much larger than Data Block (usually 4–32KB). In the most ideal case, when the Index/Filter Block is completely stored in memory, it will only be read once per SST life cycle, but when it competes with the Data Block for the Block Cache, it is likely to be re-read from the disk due to being evicted. Do it many times, resulting in very serious read amplification.
Kvrocks' previous approach was to dynamically adjust the SST-related configuration so that the SST file will not be too large, thereby avoiding the Index/Filter Block from being too large. However, the problem with this mechanism is that when the amount of data is very large, too many SST files will take up more system resources and cause performance degradation. The new version of Kvrocks optimizes this and opens the related configuration of the Partitioned Block. The principle of the Partitioned Block is to add a secondary index to the Index/Filter Block. When reading the Index or Filter, the secondary index is first to read into the memory, and then Find the required partition Index Block according to the secondary index, and load it into the Block Cache.
The advantages of Partitioned Block are as follows:
- Increase the cache hit rate: Large Index/Filter Block will pollute the cache space. The large Block will be partitioned, allowing the Index/Filter Block to be loaded at a finer granularity, thereby effectively using the cache space
- Improve cache efficiency: The partition Index/Filter Block will become smaller, the lock competition in the Cache will be further reduced, and the efficiency under high concurrency will be improved
- Reduce IO utilization: When the cache Miss of the index/filter partition, only a small partition needs to be loaded from the disk. Compared with the Index/Filter Block that reads the entire SST file, this will make the load on the disk smaller
Related configuration:
format_version = 5
index_type = IndexType::kTwoLevelIndexSearch
BlockBasedTableOptions::partition_filters = true
cache_index_and_filter_blocks = true
pin_top_level_index_and_filter = true
cache_index_and_filter_blocks_with_high_priority = true
pin_l0_filter_and_index_blocks_in_cache = true
optimize_filters_for_memory = true
Data compression optimization
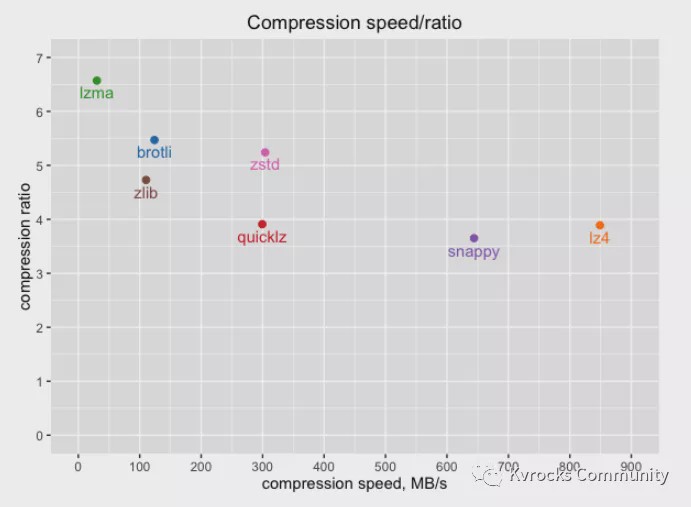
RocksDB compresses the data when it's placed on the disk. We compared and tested different compression algorithms on Kvrocks and found that different compression algorithms have a great impact on performance, especially when CPU resources are tight, which will significantly increase latency.
The following figure shows the test data of compression speed and compression ratio of different compression algorithms:
In Kvrocks, compression is not set for the SST of the L0 and L1 layers, because these two layers have a small amount of data. Compressing the data at these levels cannot reduce a lot of disk space, but not compressing the data at these levels can save CPU. Each Compaction from L0 to L1 needs to access all files in L1. In addition, the range scan cannot use Bloom Filter, and it needs to find all files in L0. If you do not need to decompress when reading data in L0 and L1, and writing data in L0 and L1 do not need to be compressed, then these two frequent CPU-intensive operations will take up less CPU, compared to the disk space saved by compression, it is more profitable.
Considering the trade-off between compression speed and compression ratio, Kvrocks mainly chooses two algorithms, LZ4 and ZSTD. For other levels, LZ4 is used because the compression algorithm is faster and the compression ratio is higher. RocksDB officially recommends using LZ4. For scenes with large data volume and low QPS, the last layer will be set to ZSTD to further reduce storage space and reduce costs. The advantage of ZSTD is that the compression ratio is higher and the compression speed is faster.
Cache optimization
For the simple data type (String type), the data is directly stored in Metadata CF, while for complex data types, only the metadata is stored in Metadata CF, and the actual data is stored in Subkey CF. Kvrocks previously allocated the same size of Block Cache to these two CFs by default. However, the online scene is complicated and the user's data type cannot be predicted, so it is not possible to allocate an appropriate Block Cache size to each CF in advance. If users use simple types and use complex types in different proportions, the Block Cache hit rate will decrease. Kvrocks shared the same large Block Cache to achieve a 30% improvement in the command rate of the Cache. In addition, Row Cache is also introduced to deal with the problem of hotkeys. RocksDB checks Row Cache first, then Block Cache. For scenes with hot spots, data will be stored in Row Cache first to further improve Cache utilization.
Key-Value Separation
The LSM storage engine will store the Key and Value together. During the compaction process, both Key and Value will be rewritten. When the Value is large, it will cause serious write amplification problems. In response to this problem, the WiscKey paper proposed a Key-Value separation scheme. Based on this paper, the industry also realized the KV separation of LSM-type storage engines, such as RocksDB's BlobDB, PingCAP's Titan engine, Quantum engine used by Baidu's UNDB.
RocksDB 6.18 version re-implemented BlobDB (RocksDB's Key-Value separation scheme), integrated it into the main logic of RocksDB, and has been improving and optimizing BlobDB related features. Kvrocks introduced this feature in 2.0.5 to deal with scenarios with large values. Tests show that when Kvrocks turns on the KV separation switch, for the scenario where Value is 10KB, the write performance is increased by 2.5 times, and the read performance is not attenuated; the larger the value, the greater the write performance improvement, and the write performance is improved when the Value is 50KB. 5 times.
Related configuration:
ColumnFamilyOptions.enable_blob_files = config_->RocksDB.enable_blob_files;
min_blob_size = 4096
blob_file_size = 128M
blob_compression_type = lz4
enable_blob_garbage_collection = true
blob_garbage_collection_age_cutoff = 0.25
blob_garbage_collection_force_threshold = 0.8
Kvrocks Roadmap
2021 is coming to an end, the related work of Kvrocks 2.0 has been basically completed, and the plan of Kvrocks 3.0 has also been listed on GitHub. This article lists the following two important features.